INDIA
INDIA
 USA
USA CANADA
CANADAITSM incident management simplified: 7 proven ways to resolve issues faster
14/04/2026
Your monitoring dashboard lights up at 2 a.m. Your on-call engineer gets paged. Users are already tweeting about downtime. By the time your team diagnoses the root cause, the damage is done. Sound familiar? Most IT teams live in this loop. Incident fires. Team scrambles. Temporary fix applied. Repeat.
ITSM incident management does not have to work this way.
With the right structure, tools, and mindset, you can cut resolution time dramatically, reduce repeat incidents, and eventually shift from reactive firefighting to proactive prevention.
In this guide, you will learn:
- What ITSM incident management really means (beyond the textbook definition)
- Why it matters more in 2025 than ever before
- The 7 proven ways to resolve IT incidents faster
- Ready-to-use templates and real-world examples
- How predictive AI is changing the entire incident management game
Contact us now
ITSM Incident Management: 7 Ways to Resolve Issues Faster
What is ITSM incident management?
ITSM incident management is the structured process of identifying, logging, diagnosing, and resolving unplanned disruptions to IT services, to restore normal operations as quickly as possible.
That is the formal version. Here is the real one.
It is everything that happens between ‘something broke’ and ‘we fixed it.’ Done well, incident management software keeps that window short, documented, and learnable. Done poorly, it creates chaos, blame, and repeated failures.
IT incident management sits within the broader IT service management (ITSM) framework, which governs how IT services are delivered and improved over time. The ITSM incident management workflow typically follows ITIL guidelines, covering detection, classification, investigation, resolution, and closure.
The difference between a team that manages incidents well and one that does not often comes down to process maturity, not technical skill.
Why ITSM incident management matters in 2025
IT systems are more interconnected than ever. One failure cascades faster than ever. And business tolerance for downtime is lower than ever.
Here is what strong ITSM incident management delivers:
- Faster mean time to resolution (MTTR) by eliminating guesswork and miscommunication
- Consistent SLA compliance because every incident follows a defined path
- Fewer repeat incidents when post-incident reviews feed into problem management
- Better end-user experience because people are kept informed throughout
- Audit-ready documentation that satisfies compliance requirements
Beyond these benefits, the competitive reality is simple. Organizations that invest in mature ITSM service management recover from incidents faster. That speed translates directly into revenue protection, brand trust, and team morale.
When should you use a formal ITSM incident management workflow?
Not every hiccup needs a full incident process. But certain scenarios demand it. Here are the four most common situations where a structured ITSM incident management workflow pays off immediately.
When a critical production system goes down
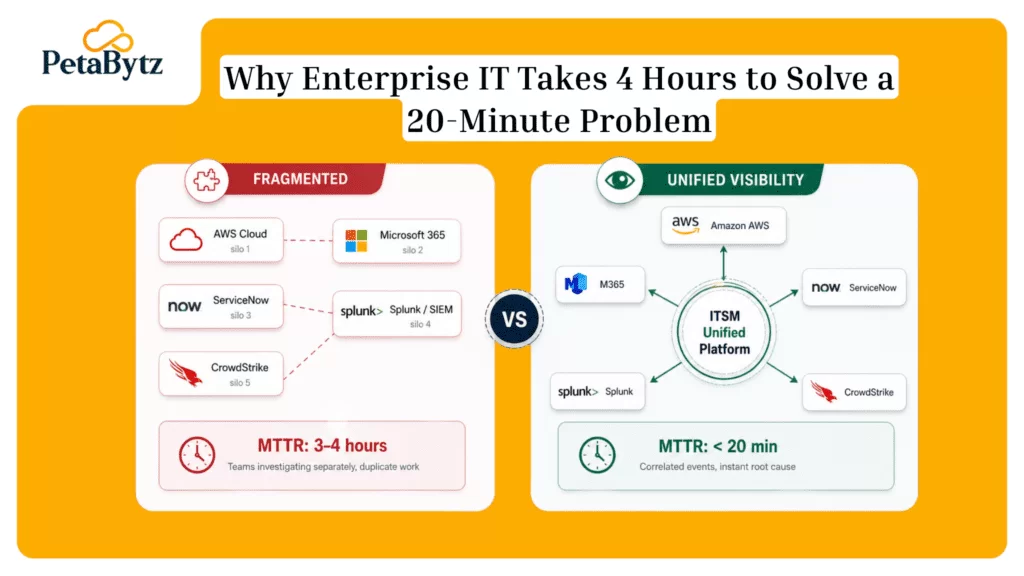
This is the classic high-priority incident. A production server is down, an application is unreachable, or a database is returning errors. Without a defined ITSM incident management workflow, teams waste valuable minutes figuring out who to call and what to do first. A structured process eliminates that hesitation.
When multiple users are reporting the same issue
A wave of similar tickets is a signal, not just noise. Formal incident management allows you to correlate reports, recognize a pattern quickly, and escalate to a major incident before the situation worsens. Without it, every ticket gets treated as isolated, and the real problem gets missed.
When SLA breach risk is high
If a customer or internal SLA is at risk, you need escalation rules that activate automatically. ITSM incident management workflows can trigger notifications, reassign ownership, and document every action, so your team can demonstrate due diligence even if the SLA is ultimately missed.
When a change or deployment causes instability
Post-deployment incidents are among the most common and most avoidable. A structured IT incident management process tied to change management gives you a clear rollback path and a documented audit trail, which matters enormously for regulated industries.
Key elements of a strong ITSM incident management process
Great incident management does not happen by accident. It is built on six core components.
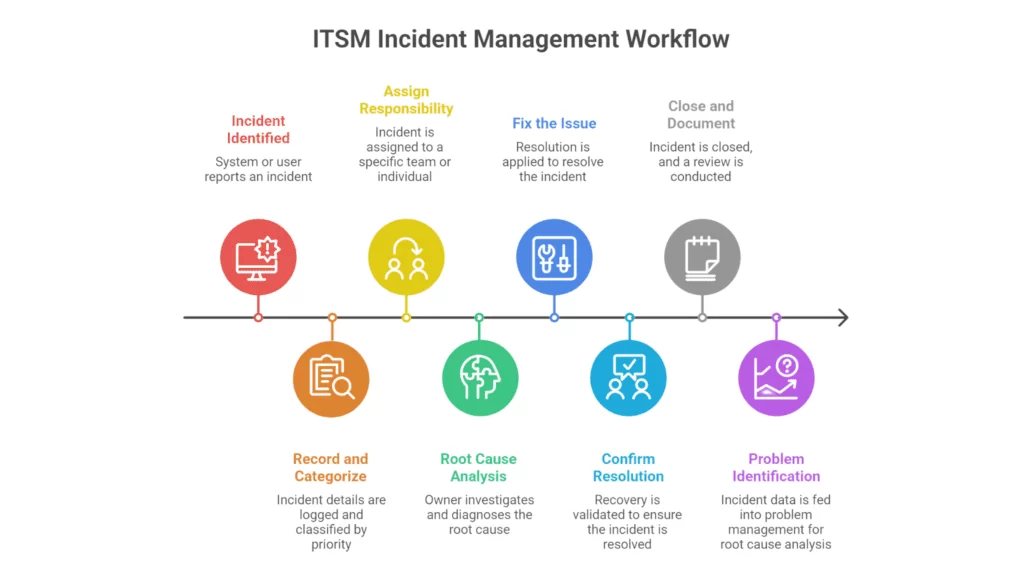
1. Incident detection and logging
Every incident starts with detection. This can come from automated monitoring alerts, user-submitted tickets, or IT staff observations. The critical step is logging every incident immediately, with a timestamp, affected service, priority level, and initial description. Gaps in logging create blind spots in your data, making it harder to improve over time.
2. Incident classification and prioritization
Not all incidents are equal. A P1 production outage affecting 10,000 users is not the same as a P4 software bug one person reported. Classification defines what type of incident it is. Prioritization determines how fast it gets attention. A clear priority matrix, based on impact and urgency, keeps your team focused on what matters most.
3. Incident assignment and escalation rules
Clear ownership is non-negotiable. Every incident must have one person accountable for its resolution. Escalation rules define when and how ownership transfers, such as escalating to L2 after 30 minutes or to a major incident manager if impact crosses a threshold. Without these rules, incidents fall through the cracks.
4. Investigation and diagnosis
This is where the technical work happens. Teams investigate logs, check recent changes, and run diagnostic tests to identify the root cause. Good incident management software supports this phase with historical data, linked incidents, and knowledge base articles to speed up diagnosis.
5. Resolution and recovery
Resolution means restoring service to normal or near-normal operation. This might involve a workaround, a configuration change, or a patch. The resolution should be documented in the incident record. For critical incidents, recovery validation, confirming the fix held, is just as important as the fix itself.
6. Post-incident review and closure
Closing a ticket without a review is how the same incident happens again next month. For P1 and P2 incidents, a post-incident review should capture what happened, why it happened, what fixed it, and what will prevent recurrence. This feeds directly into your problem management process and builds a knowledge base your team can actually use.
ITSM incident management: How does it work?
Real examples of ITSM incident management that work
Example 1: The repeat database timeout
A mid-size fintech company was seeing database timeout errors every three to four weeks. Each time, the L1 team resolved it by restarting the service. Tickets were closed. No review was done. When they implemented a proper ITSM incident management workflow, their problem management team linked all 11 prior incidents and traced them to a memory leak in a third-party connector. One patch eliminated the recurrence entirely.
This works because incident data without problem management analysis is just history. Connecting incidents to root causes turns data into prevention.
Example 2: The missed SLA from poor escalation
A healthcare IT team was consistently breaching SLAs on P2 incidents. Analysis showed the problem was not technical skill. It was that escalation rules were unclear. Engineers waited too long to escalate because they feared looking incompetent. After introducing defined escalation thresholds in their incident management software, automatic escalation notifications reduced average P2 resolution time by 38 percent in 90 days.
This works because ambiguity is a performance killer. Explicit rules remove hesitation and protect SLAs.
Example 3: Proactive incident prevention with monitoring alerts
A logistics company integrated their monitoring tools with their IT incident management platform. When CPU utilization on a key application server exceeded 85 percent for more than five minutes, a P3 incident was automatically created and assigned. The on-call engineer investigated and found a runaway process before users ever noticed degraded performance. Downtime was zero.
This works because automated detection + automatic ticket creation removes the detection delay that typically costs the most time.
Example 4: Communication failures during a major outage
A retail company had a two-hour platform outage during a peak sales event. Technically, the resolution was fast, under 45 minutes. But stakeholders and customers were not informed until the incident was already resolved. The reputational damage was significant. After implementing a major incident communication template with scheduled update intervals, their next outage, though longer technically, generated far fewer escalations and complaints because stakeholders were informed throughout.
This works because perception of competence during an outage is almost entirely driven by communication, not just speed.
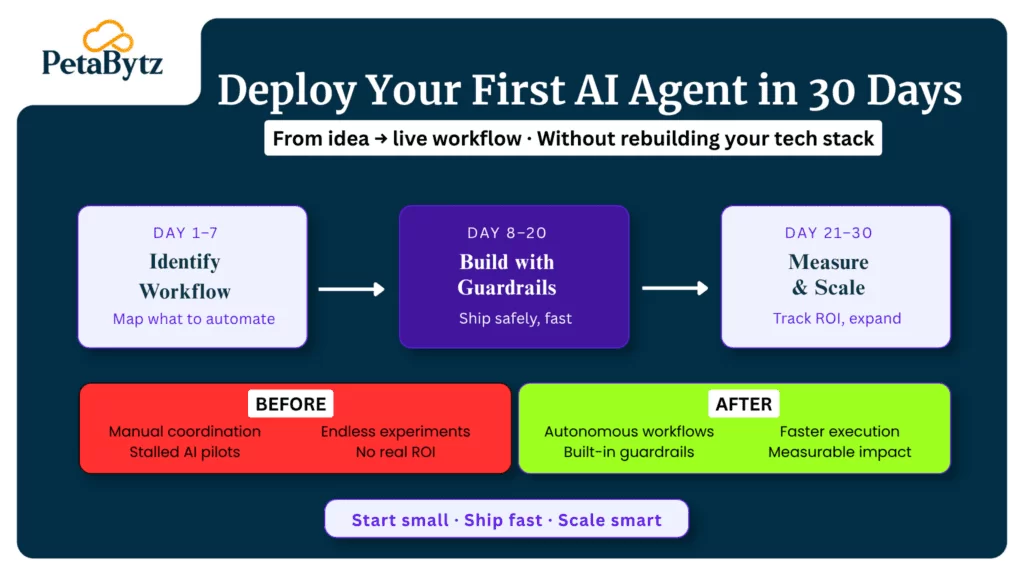
7 proven best practices to improve ITSM incident management
Define your priority matrix before the next incident
Most teams argue about priority in the middle of an incident. That wastes time and creates friction. Build a priority matrix based on two dimensions: business impact and urgency. Map P1 through P4 to specific criteria before anything goes wrong. Laminate it if you have to.
Use one platform for detection, logging, and communication
Tool sprawl kills efficiency. When your monitoring alert goes to Slack, the ticket goes to one platform, and stakeholder updates go to email, context gets lost. Modern incident management software consolidates these into a single ITSM incident management workflow, with full context available in one place.
Automate what you can, starting with notifications and ticket creation
Manual processes are slow and inconsistent. Start by automating the highest-frequency low-complexity steps: alert-to-ticket creation, SLA countdown triggers, and escalation notifications. This alone can shave 15 to 30 minutes off average resolution time.
Build and actively maintain a knowledge base
If your engineers are solving the same incidents from scratch every time, you have a knowledge problem. After each significant incident, document the diagnosis steps and the fix in your knowledge base. When the same issue appears again, the resolution time drops dramatically because the answer is already there.
Run post-incident reviews on every P1 and P2
Post-incident reviews are not about blame. They are about learning. Keep them blameless, focused on process and systems rather than individuals. The output should be specific action items with owners and deadlines, not a vague list of ‘areas to improve.’ Disciplined post-incident reviews are the single most impactful practice for reducing incident frequency over time.
Track MTTR and MTTD as team health metrics
Mean time to resolution (MTTR) and mean time to detect (MTTD) are the two metrics that tell you how healthy your IT incident management process really is. Review them monthly. Investigate spikes. Celebrate improvements. These numbers move when your process improves, and they stall when it does not.
Connect incident management to problem and change management
Incident management in isolation is a treadmill. You fix the same things over and over. The breakout happens when incident data feeds your problem management process, which identifies root causes and drives permanent fixes through change management. This integration is the foundation of mature ITSM service management.
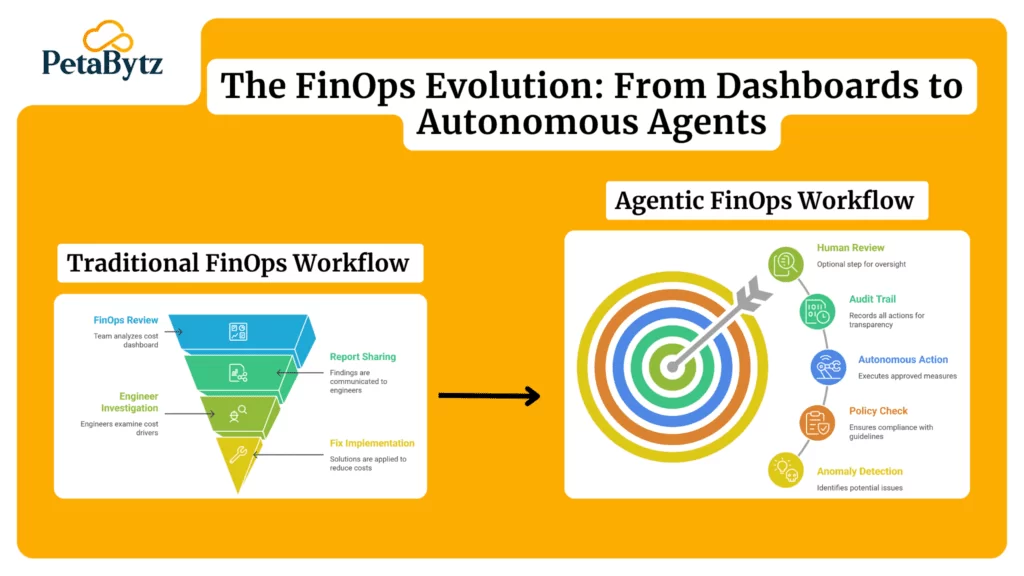
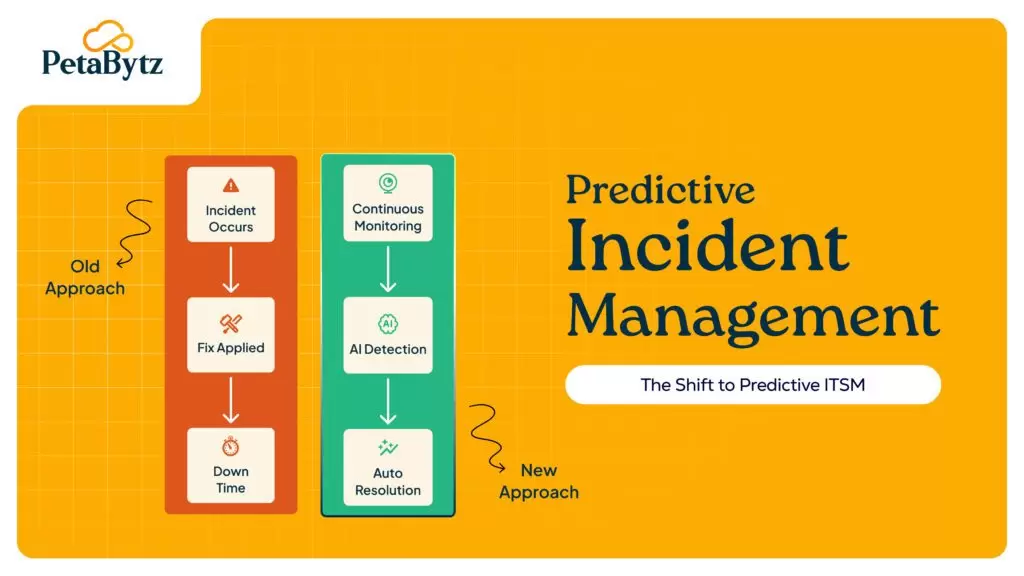
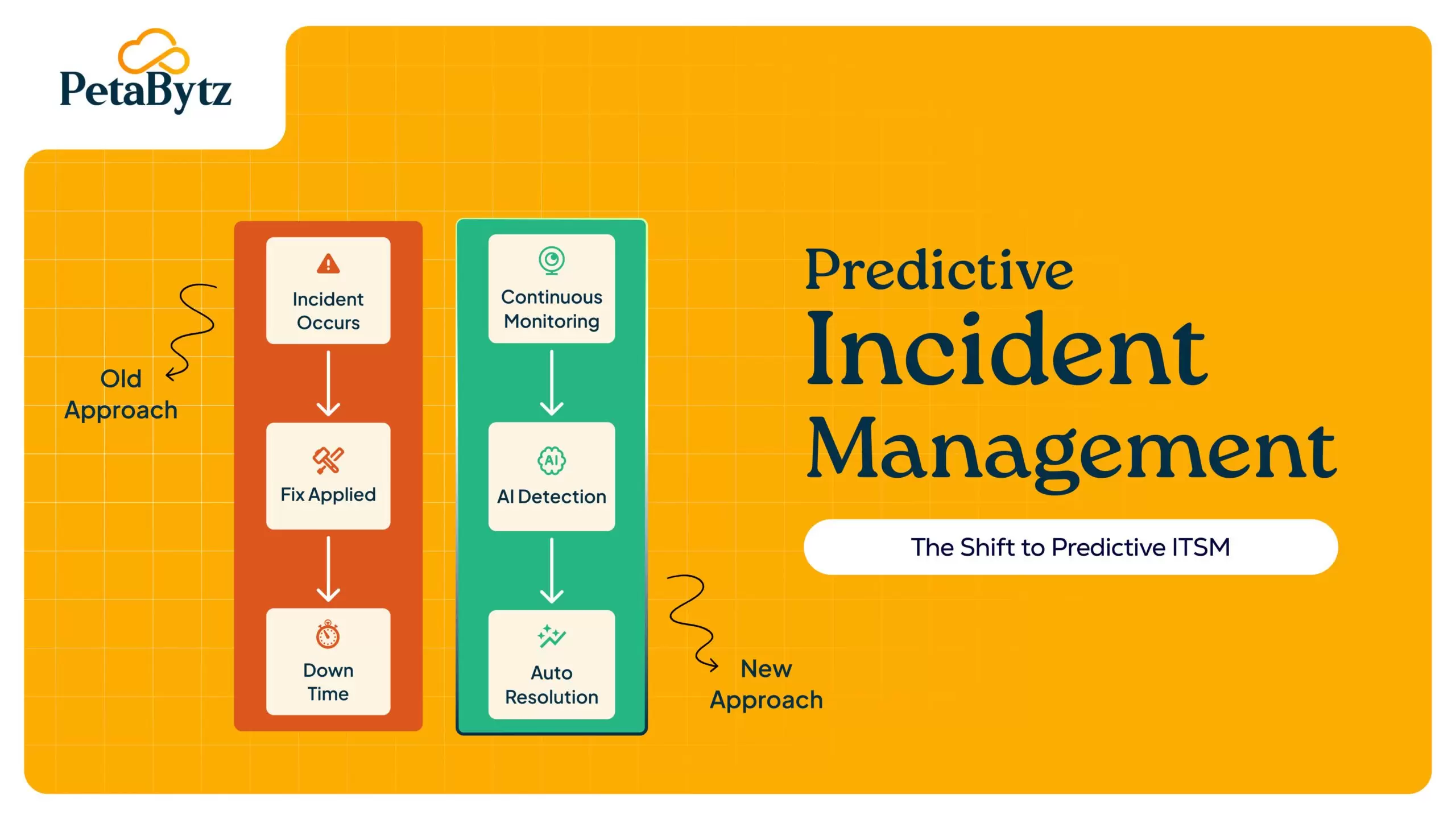
How predictive AI is changing ITSM incident management
Everything above makes your reactive process faster and smarter. But the biggest shift in IT incident management right now is not about reacting better. It is about not reacting at all.
Traditional ITSM incident management starts when something breaks. Predictive ITSM starts before that.
By continuously analyzing system metrics, log data, and historical incident patterns, AI-driven systems can identify early warning signals that no human would catch in time. A performance anomaly at 11 pm. becomes a predictive alert at 10:45 pm. The team investigates and resolves the underlying condition before any user notices.
This shift has four observable effects on ITSM service management:
- Incidents that would have occurred simply do not happen
- Resolution workflows can be automated or pre-staged for likely failures
- SLA performance improves because fewer critical incidents ever breach thresholds
- IT teams spend less time firefighting and more time on strategic work
This is precisely the direction that organizations like Petabytz Technologies are building toward. Their predictive incident management approach combines AI-driven anomaly detection, automated resolution workflows, and intelligent monitoring to help enterprises move from reactive response to proactive prevention. The goal is not just faster ITSM incident management. It is fewer incidents to manage in the first place.
Website: www.petabytz.com
Email: info@petabytz.com
Conclusion
You do not need to overcomplicate this.
Start with a clear priority matrix. Define escalation rules. Document every incident. Run post-incident reviews. Build your knowledge base. Measure MTTR and MTTD. Those six steps, done consistently, will transform your ITSM incident management process.
Once those fundamentals are solid, you are ready for the next evolution. Predictive AI does not replace good incident management process. It amplifies it. The teams that will win in 2025 and beyond are those that combine disciplined ITSM service management with intelligent, data-driven prevention.
The question is not whether your IT incident management can be better. It can. The question is how fast you are willing to move.
What is the difference between incident management and problem management in ITSM?
Incident management focuses on restoring service as quickly as possible. Problem management focuses on finding and eliminating the root cause to prevent future incidents. In the ITSM incident management workflow, incidents should feed into problem management. If you only do incident management, you keep fixing the same things. Problem management breaks that cycle by addressing why incidents keep happening.
What does good incident management software need to include?
At minimum, incident management software should provide automated ticket creation, priority classification, SLA tracking, escalation rules, and post-incident reporting. The best tools also integrate with monitoring platforms, support knowledge base linking, and offer analytics dashboards so teams can track MTTR, MTTD, and incident trends over time. The right tool is the one your team will actually use consistently.
How do you reduce MTTR in IT incident management?
The biggest gains in MTTR come from three areas. First, faster detection through automated monitoring reduces the gap between when an incident starts and when anyone knows about it. Second, a well-maintained knowledge base means engineers spend less time diagnosing known issues. Third, clear escalation rules prevent incidents from sitting idle while people decide who owns them. Combine all three and MTTR improvements are significant.
What is predictive incident management and how is it different from traditional ITSM?
Traditional ITSM incident management is reactive. It starts when something fails or a user reports a problem. Predictive incident management uses AI and machine learning to analyze system data continuously and identify patterns that suggest a failure is coming. This allows teams to intervene before disruption occurs. The result is fewer incidents, lower MTTR for those that do occur, and better overall system reliability.
Recent Posts